
ACM MM 2025 | 高德FingER: 具有细粒度推理和内容感知的AI生成视频质量评估方法
发布时间:2025-08-06 09:02分类: 综合 浏览:13评论:0

ACM International Conference on Multimedia (ACM MM)是计算机科学多媒体领域的顶级国际会议,是中国计算机学会(CCF)推荐的A类国际学术会议。ACM MM 2025将于2025年10月27日-10月31日在爱尔兰都柏林举办,ACM MM 2025共有4672份有效投稿,录用1251篇,录取率为26%。高德团队2篇论文被收录。


【论文标题】FingER: Content Aware Fine-grained Evaluation with Reasoning for AI-Generated Videos
【论文链接】https://arxiv.org/pdf/2504.10358
【开源地址】https://github.com/AMAP-ML/FingER
01
研究背景

图1:AI生成视频的局部缺陷和多模态大模型对细粒度问题的回答
当前较好的视频生成模型(如:Kling, Vidu等)通常在视频整体效果上有不错的保持,但在局部区域仍会出现缺陷(如图 (a) 所示,女孩的手部出现扭曲,存在时间上的不一致),发现这类细粒度的视频质量问题往往需要模型更深入的语义理解。
对于多模态大模型而言(如:GPT-4o等),即使提供详细的提示词,通过单纯的打分(图 (b)),或者实体级别(Entity-level)的问题(图 (c)),GPT-4o 仍未能识别出女孩手部变形的问题。
图 (d) 则展示了我们的工作FingER可以较好地回答实体级别的问题,并提供可解释性的思考过程。
02
核心贡献

图2:FingER评估框架,FingER-Instruct-60k数据集,以及本文探讨的多种训练方式(带冷启动的 GRPO 训练)
核心贡献如下:
【实体粒度的评估框架]】我们提出了一种细粒度的 AI 生成视频质量评估框架 FingER,包括实体粒度(Entity-level)的问题生成模块和提供可解释性思考过程的多模态大模型。并结合视觉质量(Visual quality),文本与视频的对齐程度(Text-to-video alignment),时间一致性(Temporal consistency),事实一致性(Factual consistency)以及视频动态程度(Dynamic degree)这五个方面,对 AI 生成视频进行质量评估。
【细粒度推理数据集】我们提出了用于 AI 生成视频质量评估的数据集 FingER-Instruct-60k,包括:3.3k AI 生成视频(来自 Kling、Vidu、Luma 等模型),以及 60k 实体粒度的问答对(Q/A pairs),每个问答对还带有推理过程(对回答的解释)。该数据集能够覆盖较为复杂的场景(人类活动、物体关系等),相应实体级别的问答对和推理过程通过人工校验确保了数据标注质量;为 AI 生成视频质量评估领域提供了高质量的标注数据,助力多模态大模型对视频局部缺陷细粒度理解能力的提升。
【逻辑推理能力增强的训练方法】我们探讨了多种训练方式,旨在提高 MLLMs 在细粒度视频推理中的能力,包括:SFT(监督微调):仅学习答案标签("Yes / No");SFT + Reasoning:同时学习答案与推理过程;GRPO(组相对策略优化):引入强化学习优化,并结合冷启动(Cold-start)策略(基于 SFT 后的模型)。特别是首次将 GRPO 训练引入 AI 生成视频质量评估,证明其在提升模型推理和泛化能力方面较为有效。
【SoTA 的性能表现】实验验证了我们方法的有效性,在仅使用十分之一训练视频的情况下(相较于 VideoScore 等方法),在公共评测集上达到了较好的性能,体现了 FingER 良好的泛化能力。
03
实验结果
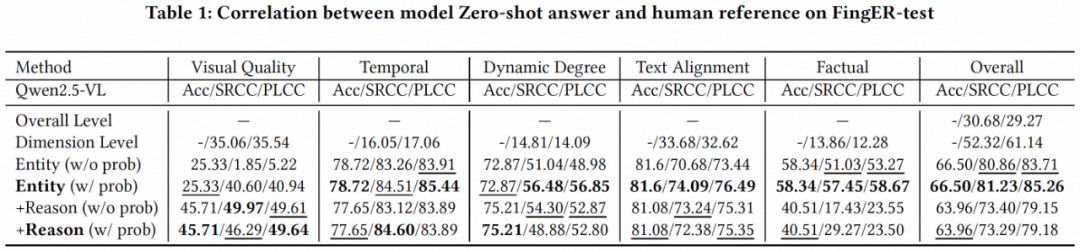
表1展示了我们在 Qwen2.5-VL-7B 的基模上进行 Zero-shot 测试的结果。我们对评价方式的粒度逐渐细化,对比了对视频整体维度(Overall level)/ 多方面维度(Dimension level)/ 实例维度(Entity level)进行打分(问答)在所提出的 FingER-test 数据集上的效果。实验结果表明,在与人工标注结果的一致性上(SRCC/PLCC),实例维度打分的性能远高于整体维度和多方面维度。此外,在引入输出推理过程之后,基模在视觉质量(Visual quality)方面的性能有所提升,但在事实一致性(Factual consistency)方面的性能有明显下降,表明基模对 AI 生成视频的理解仍存在局限性。
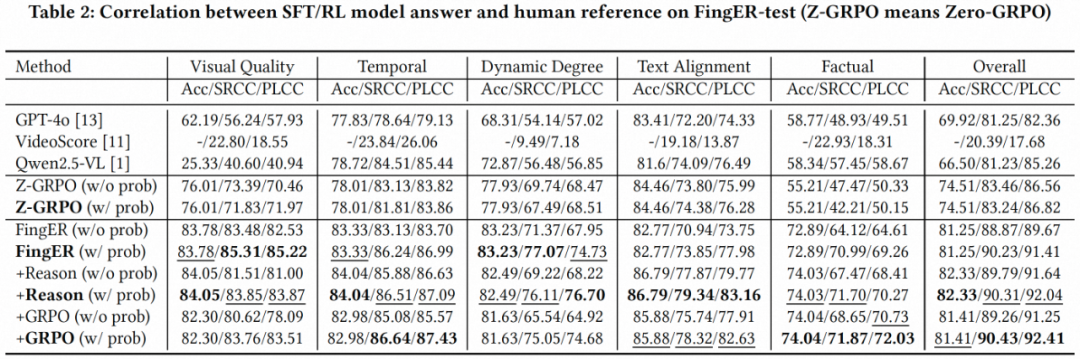
表2展示了我们基于不同训练方法对 Qwen2.5-VL-7B 指令微调后在所提出的 FingER-test 数据集上的实验结果。对比只回答 "Yes / No"(表中 FingER)和额外输出得到答案的推理过程(表中 + Reason),在文本与视频的对齐程度方面(Text Alignment)有明显的性能提升(SRCC/PLCC: 从 73.85/77.98 提升至 79.34/83.16),表明对模型输出的推理过程进行监督微调能够提升模型对细粒度实体的理解能力。
更进一步,我们使用监督微调后的模型作为冷启动(Cold-start),结合 GRPO 算法进行强化学习优化,模型(表中 + GRPO)在时间一致性(Temporal)/ 事实一致性(Factual)方面的性能得到了进一步提升,验证了强化学习对模型在深层推理方面的优化作用。
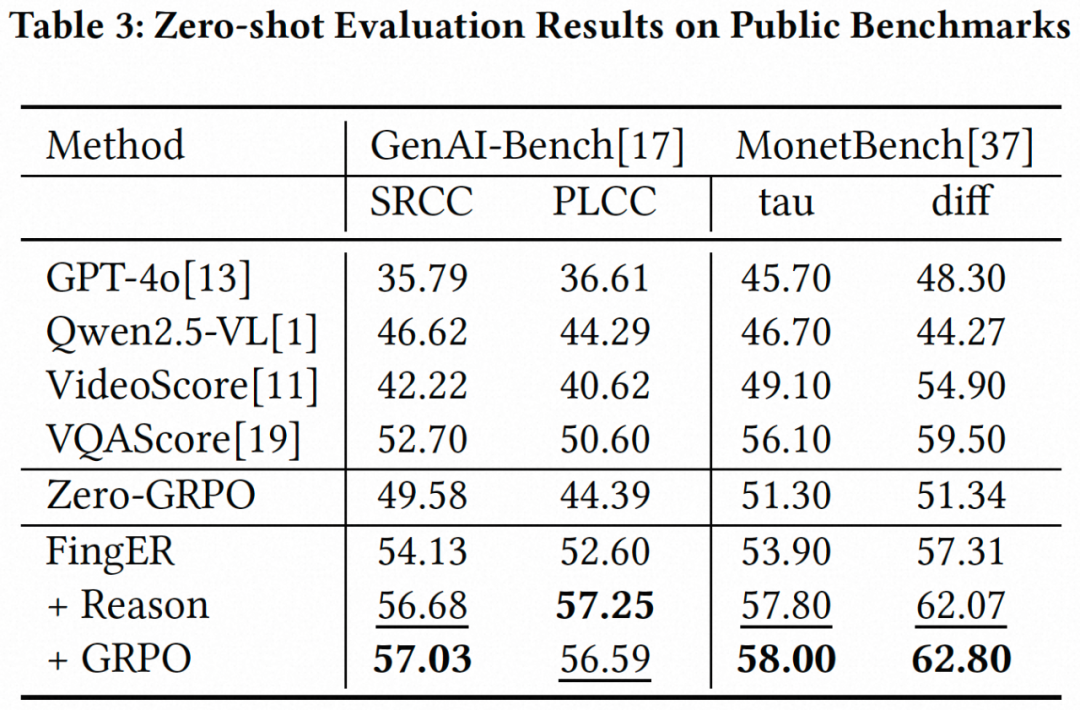
表3展示了FingER在公共评测集上的Zero-shot性能。FingER在未见过的视频生成模型产生的数据集上仍具有SoTA的性能,在 GenAI-Bench上的SRCC/PLCC达到57.03/56.59,在MonetBench上的tau/diff达到58.00/62.80 的性能,均超过现有方法VideoScore 及VQAScore。

图3:FingER-test 数据集上的部分模型推理结果
图3展示了FingER对不同实体及评价维度的问题及回答(带有推理过程)。
04
总结
在本工作中,我们强调了引入细粒度推理对 AI 生成视频质量评估的重要性,并提出了 FingER,一个针对AI 生成视频的实体级细粒度质量评估框架,且具有五个不同的评估维度。为了缓解真实视频与 AI 生成视频之间的数据分布差异,我们构建了高质量的训练数据集 FingER-Instruct-60k,该数据集由当前较为先进的视频生成模型生成的 3.3k 视频和 60k 实体级问题/回答/推理过程的数据对组成。基于这一数据集,我们探索了多种训练方法,以最大程度激发出模型的推理能力,包括:SFT + Reasoning,Zero-GRPO 和带有冷启动的 GRPO。实验表明,使用带有冷启动的 GRPO 训练后,我们的方法不仅在提出的 FingER-test 测试集上达到了最佳性能,而且在两个公共评测集上超越了其它方法和闭源多模态大模型。值得注意的是,我们仅使用了 3.3k 视频训练样本便实现了 SoTA 的性能。
欢迎加入


#顶会 #论文 #AI生成 #视频生成 #ACMMM2025 #视频质量评估 #视频内容理解 #多模态大模型 #强化学习 #细粒度理解